전세계 최대 소셜 네트워크 서비스라할 수 있는 페이스북의 개발자 컨퍼런스(f8)이 있었다. 뉴스에 오르내리지는 않았지만, 페이스북 로그인 후 첫화면에 나오는 친구들의 최근 소식을 요약해서 전달해 주는 알고리즘인 EdgeRank에 대한 내용이 있었다.
친구들의 모든 활동을 다 보여줄 수 없기 때문에 가장 중요하고 볼 만하다고 여겨지는 것만을 선별하는 알고리즘이다. PageRank에 이후에 수 많은 Rank들이 나와서 이름이 낯설지는 않지만 Edge라는 건 특정 기사(Object)에 어떤 상호 작용(Status)이 추가 될 때 새로운 것이 덧붙여지기 때문에 붙인 이름 같다.
아이디어는 아주 간단해서 (1)affinity score: 새로운 소식을 업데이트 한 사람과의 친밀도 (2) weight: 각 상호작용의 가중치 (3) time: 올라온 시간의 세 가지 곱의 합으로 되어 있다.

즉, 잘 알고 있는(상호 작용)이 최근에 여러 사람의 댓글(Comment)이나 추천(Like)를 받은 게 나의 뉴스피드에 나타난다는 말이다.
예전에 Social Interaction Ontology를 설계 할 때, 상호 작용은 가중치를 부여해야 하는데 그 가중치를 정하는 공식은 매우 중요하다. 페이스북에서는 Like가 코멘트 보다 가중치가 낮다고 산정하는 것 같다. 하지만, 트위터에서 RT가 코멘트 보다 가중치가 낮을까? 미투데이에서 미투 버튼이 댓글 보다 가중치가 낮을까? 이건 고민해 봐야할 문제다.
소셜 네트웍에서 알고리즘을 만들 때, 휴먼 팩터를 고려하는 건 굉장히 중요한 문제이다.
Daum View(블로거뉴스)의 열린 편집을 통한 베스트 뉴스를 뽑는 알고리즘 (Open Editing Algorithm: A Collaborative News Promotion Algorithm based on Users' Voting History)에 따르면 추천 버튼을 누르는 사람의 성향과 추천을 받아 베스트 뉴스에 오르는 여러 과정 중의 추천 버튼을 누르는 방법을 구별해서 점수를 계산하고 있다.
 이 알고리즘 역시 매우 간단하다. 베스트글을 한번이라도 써본 사람(M)과 일반 블로거(N)가 특정 글을 베스트에 올릴 때 유효했던 추천(A)에 가중치를 두어 나머지 추천(B)를 토대로 그 사람이 했던 추천 점수를 계산 하게 된다. (여기서 c와 c'는 표본 에디터에서 산출한 상수 값).
이 알고리즘 역시 매우 간단하다. 베스트글을 한번이라도 써본 사람(M)과 일반 블로거(N)가 특정 글을 베스트에 올릴 때 유효했던 추천(A)에 가중치를 두어 나머지 추천(B)를 토대로 그 사람이 했던 추천 점수를 계산 하게 된다. (여기서 c와 c'는 표본 에디터에서 산출한 상수 값).
그런 다음 사람이 충분히 읽지 않고 추천한 짧은 시간에 추천(D)과 베스트 글 이후의 유사한 추천(DB)를 뺀 값이다. 즉, 추천 점수는 내용을 충분히 읽고 추천한 글 중에 베스트 글을 쓴 사람이 베스트 글이 될만한 딱 그 시점에 추천이 많은 경우 올라갈 수 있다는 의미이다.
웹 서비스가 사회적 인간적 요인들이 많아지면서 공학적 알고리즘에 인간적 요인을 배려를 하기 시작한 건 그리 오래된 일은 아닌 것 같다.
예전에 장난 삼아 '떠날 직원 알아내는 알고리즘'을 쓴 적이 있는데 많은 분들이 공감했던 기억이 난다.
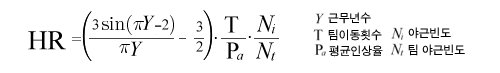 즉, 홀수(1,3,5...)년차에 쯤에 그 동안 팀 이동 횟수가 많고, 평균 연봉 인상율이 낮은 사람 중 야근 빈도가 팀원들의 야근 빈도 보다 높을 때 이직할 확률이 높다는 우스개소리였다.
즉, 홀수(1,3,5...)년차에 쯤에 그 동안 팀 이동 횟수가 많고, 평균 연봉 인상율이 낮은 사람 중 야근 빈도가 팀원들의 야근 빈도 보다 높을 때 이직할 확률이 높다는 우스개소리였다.
아주 복잡한 수학 처럼 보이지만, 아주 단순한 경험의 산물이다. 결국 문제는 어떻게 검증(Evaluation)하느냐 하는 것이다. 이것이 바로 연구의 성패를 가늠하는 것이고, 데이터를 가진 자만이 할 수 있는 우월함 아닐까?
친구들의 모든 활동을 다 보여줄 수 없기 때문에 가장 중요하고 볼 만하다고 여겨지는 것만을 선별하는 알고리즘이다. PageRank에 이후에 수 많은 Rank들이 나와서 이름이 낯설지는 않지만 Edge라는 건 특정 기사(Object)에 어떤 상호 작용(Status)이 추가 될 때 새로운 것이 덧붙여지기 때문에 붙인 이름 같다.
아이디어는 아주 간단해서 (1)affinity score: 새로운 소식을 업데이트 한 사람과의 친밀도 (2) weight: 각 상호작용의 가중치 (3) time: 올라온 시간의 세 가지 곱의 합으로 되어 있다.
즉, 잘 알고 있는(상호 작용)이 최근에 여러 사람의 댓글(Comment)이나 추천(Like)를 받은 게 나의 뉴스피드에 나타난다는 말이다.
예전에 Social Interaction Ontology를 설계 할 때, 상호 작용은 가중치를 부여해야 하는데 그 가중치를 정하는 공식은 매우 중요하다. 페이스북에서는 Like가 코멘트 보다 가중치가 낮다고 산정하는 것 같다. 하지만, 트위터에서 RT가 코멘트 보다 가중치가 낮을까? 미투데이에서 미투 버튼이 댓글 보다 가중치가 낮을까? 이건 고민해 봐야할 문제다.
소셜 네트웍에서 알고리즘을 만들 때, 휴먼 팩터를 고려하는 건 굉장히 중요한 문제이다.
Daum View(블로거뉴스)의 열린 편집을 통한 베스트 뉴스를 뽑는 알고리즘 (Open Editing Algorithm: A Collaborative News Promotion Algorithm based on Users' Voting History)에 따르면 추천 버튼을 누르는 사람의 성향과 추천을 받아 베스트 뉴스에 오르는 여러 과정 중의 추천 버튼을 누르는 방법을 구별해서 점수를 계산하고 있다.
그런 다음 사람이 충분히 읽지 않고 추천한 짧은 시간에 추천(D)과 베스트 글 이후의 유사한 추천(DB)를 뺀 값이다. 즉, 추천 점수는 내용을 충분히 읽고 추천한 글 중에 베스트 글을 쓴 사람이 베스트 글이 될만한 딱 그 시점에 추천이 많은 경우 올라갈 수 있다는 의미이다.
웹 서비스가 사회적 인간적 요인들이 많아지면서 공학적 알고리즘에 인간적 요인을 배려를 하기 시작한 건 그리 오래된 일은 아닌 것 같다.
예전에 장난 삼아 '떠날 직원 알아내는 알고리즘'을 쓴 적이 있는데 많은 분들이 공감했던 기억이 난다.
아주 복잡한 수학 처럼 보이지만, 아주 단순한 경험의 산물이다. 결국 문제는 어떻게 검증(Evaluation)하느냐 하는 것이다. 이것이 바로 연구의 성패를 가늠하는 것이고, 데이터를 가진 자만이 할 수 있는 우월함 아닐까?
'소셜 웹' 카테고리의 다른 글
| 소셜 친구 추천의 한계 (3) | 2010.09.13 |
|---|---|
| 과학자를 위한 소셜 서비스 (0) | 2010.02.18 |
| 소셜 검색 알고리듬 찾기 (3) | 2010.02.12 |
| HITS 알고리듬과 소셜 네트웍 (1) | 2009.05.08 |